
Kwai — разработчик генеративного видеоинструмента Kling AI и одна из крупнейших в Азии платформ коротких видео и стриминга: свыше 400 млн ежедневно активных пользователей. Параллельно с «тиктокоподобной» моделью у компании развитый рекламный бизнес.
Ранее на блоге VeloDB разбирали, как Kwai перевёл часть аналитики с ClickHouse на Apache Doris и вывел в единый lakehouse порядка 1 млрд запросов в сутки с ускорением до 6× относительно прежней системы. С тех пор использование Doris расширилось: под него мигрировали не только ClickHouse, но и Elasticsearch.
В рекламной платформе долгое время соседствовали ClickHouse и Elasticsearch. По схеме, отражённой в архитектурных материалах Kwai, данные рекламных материалов (тексты и документы) проходили через MySQL и Elasticsearch, а метрики эффективности (показы, клики, расходы) хранились в ClickHouse. При выполнении запросов ClickHouse через механизм внешних таблиц объединял данные из обеих сторон. По мере роста объёмов Elasticsearch начал «проседать»: до 35% запросов становились медленными, средняя задержка доходила до 1,4 с, росла стоимость сопровождения, а сквозной observability между ClickHouse и Elasticsearch не хватало.
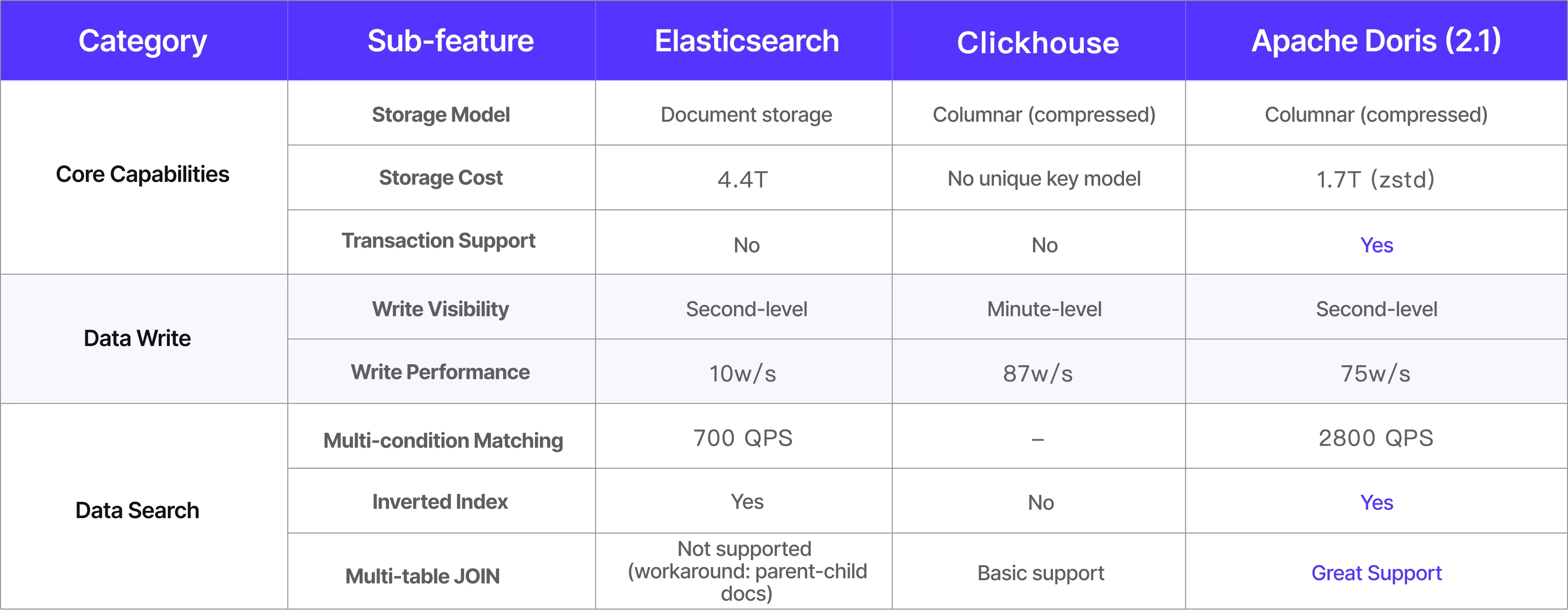
Чтобы закрыть эти проблемы, команда Kwai сравнила Apache Doris, ClickHouse и Elasticsearch «в лоб». ClickHouse первым выбыл: для сценария обновления рекламных материалов нужны были unique key updates, которых в требуемом виде не было. В паре Elasticsearch vs Doris победил Doris по пропускной способности записи, задержкам чтения, эффективности хранения и простоте эксплуатации.
После миграции с ClickHouse и Elasticsearch на Apache Doris Kwai получил:
- Снижение задержки запросов на 64–90% — на странице keyword promotion в среднем −64%, на creative promotion — до −90%.
- Пропускная способность записи выше в ~3 раза, пиковая потоковая загрузка в одну таблицу — до 3 млн строк/с на узел.
- Эффективность хранения выше примерно на 60% относительно Elasticsearch за счёт партиционирования и ZSTD; Doris уверенно тянет таблицы на триллионы строк.
- Доля медленных запросов ниже 5% (раньше 35%).
- Время разбора инцидентов сократилось примерно на 80% за счёт унифицированной наблюдаемости.
Ниже — эволюция архитектуры, поэтапная миграция и инженерные приёмы: работа со сдвигом данных (skew), partition pruning при 10 000+ партициях и настройка конкурентности запросов.
От разрозненного стека к единому аналитическому движку
Рекламная платформа Kwai обслуживает внешних рекламодателей и e-commerce: создание кампаний, материалы, ставки и онлайн-контроль эффективности. Масштаб данных огромный: триллионы строк по материалам, ~300 млн новых строк в сутки, порядка 700 ключевых полей и более 4 000 шаблонов запросов.
Такой real-time analytics делит данные на материалы (из системы кампаний) и метрики (для аналитики эффективности). Три фактора задавали нагрузку на платформу:
- Объём: накопленные данные по материалам — сотни миллиардов строк с трендом к триллионам; один из самых тяжёлых footprint в инфраструктуре Kwai.
- Рост: только в Q1 2025 суточный приток новых данных по материалам вырос в 3,5 раза г/г — нужны высокая запись в реальном времени и эластичное масштабирование.
- Сложная модель: сотни полей по материалам, кампаниям, пользователям и измерениям эффективности; тысячи шаблонов запросов давят на совместимость и производительность движка.
Архитектура до Apache Doris
До миграции материалы жили в связке MySQL + Elasticsearch, метрики эффективности — в ClickHouse.
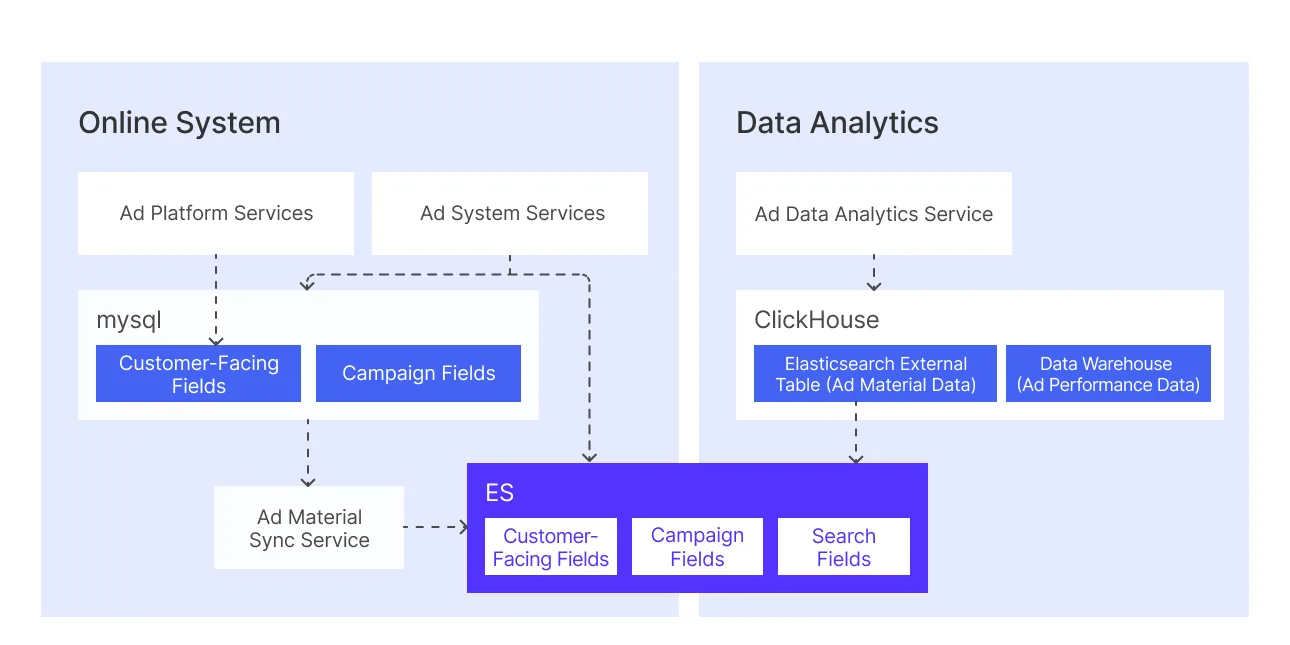
Отчёты по эффективности требовали JOIN материалов из Elasticsearch с метриками в ClickHouse. Типичный запрос трогал внешнюю таблицу Elasticsearch (материалы) и внутреннюю таблицу ClickHouse (метрики). ClickHouse разбирал часть запроса про внешнюю таблицу, транслировал её в запрос к Elasticsearch, забирал ответ по HTTP, преобразовывал в блоки и выполнял соединение с локальными данными.
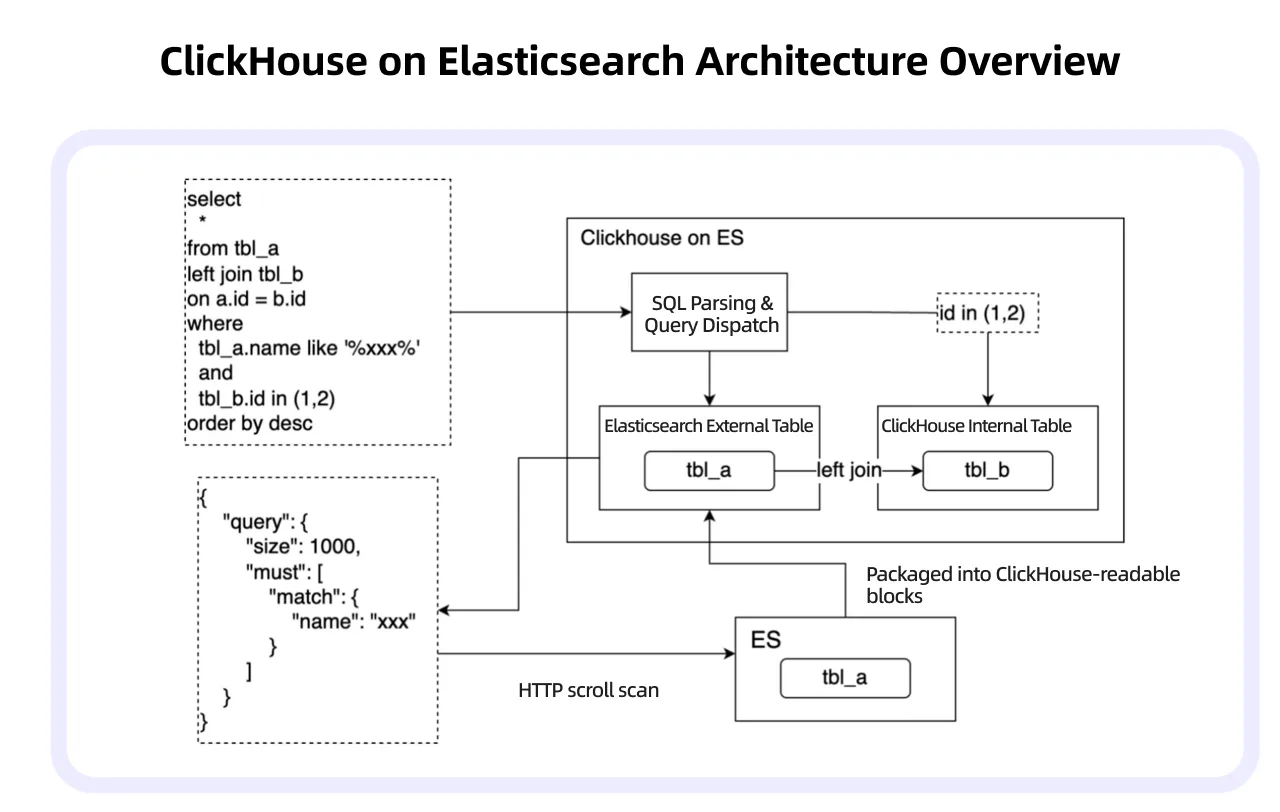
По мере роста Elasticsearch архитектура упиралась в потолок:
- Деградация запросов: до 35% «медленных», средняя задержка 1,4 с.
- Хранение: один шард Elasticsearch не тянул наборы свыше ~1 млрд строк; масштабирование = дорогое перераспределение данных.
- Операционная сложность: много компонентов в цепочке — больше мониторинга и сопровождения.
- Наблюдаемость: без сквозных трасс между ClickHouse и Elasticsearch разбор пиков задержек и рассинхронов затягивался.
Оценка альтернатив
Цели для новой системы сформулировали явно:
- Доля медленных запросов < 5%
- Разбор проблем — в минутах, а не часами
- Поддержка однотабличных наборов на триллионы строк
- Свежесть данных — в пределах 5 минут
На стресс-тестах сравнивали Doris, ClickHouse, Elasticsearch и ряд других OLAP-движков: запись, задержка чтения, компрессия и полнотекстовый поиск. ClickHouse отпал из‑за отсутствия подходящей unique key-модели для частых обновлений по первичному ключу материалов. Фокус сместился на Elasticsearch vs Apache Doris.
Doris оказался сильнее по совокупности критериев и закрыл все целевые метрики — его и выбрали как следующее поколение движка рекламной аналитики.
Bleem: унифицированный движок на Apache Doris
После выбора технологии ClickHouse и Elasticsearch заменили на Apache Doris и собрали единый аналитический слой Bleem. Поверх добавили кэш данных и сервис метаданных для внешних таблиц, чтобы запросы к lake-таблицам по скорости приблизить к внутренним.
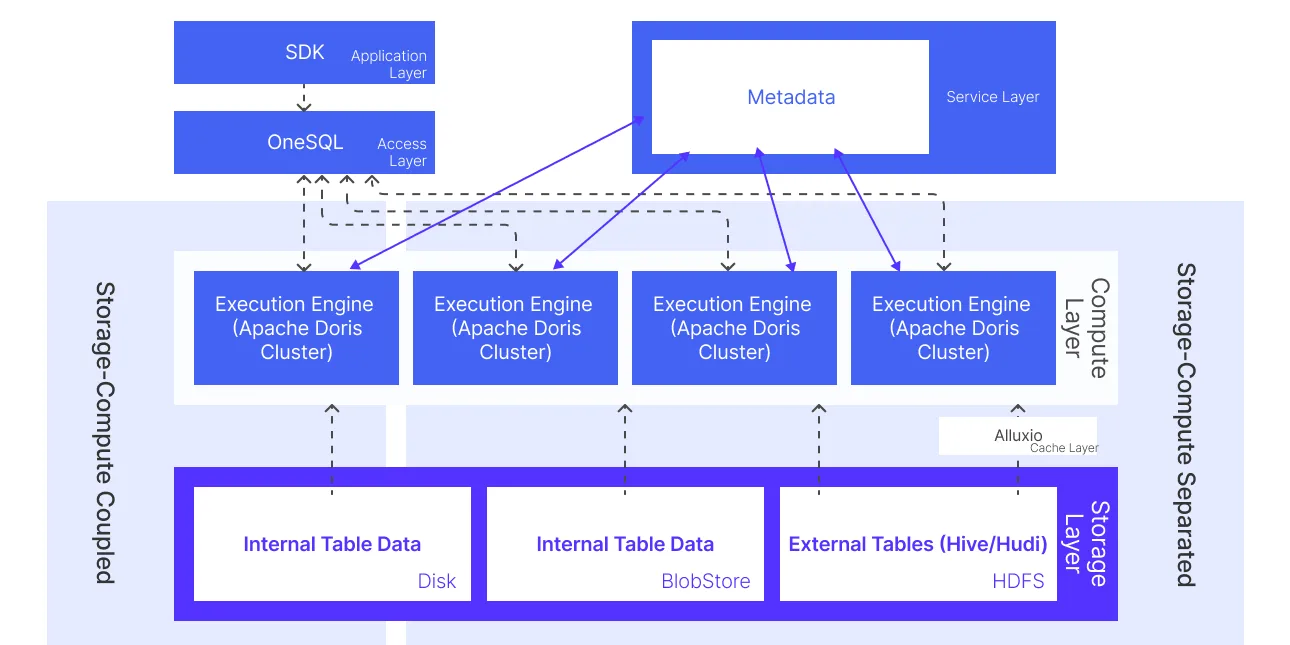
Снизу вверх архитектура Bleem выглядит так:
- Слой хранения: в озере на HDFS — Hive / Hudi; внутренние таблицы — в object storage в режиме разделения compute/storage или на локальных дисках в связанном режиме.
- Кэш: данные внешних Hive/Hudi таблиц кэшируются в Alluxio для стабильного I/O.
- Вычисления: ядро — Apache Doris; изолированные кластеры под разные команды, compute масштабируется по запросу. Lakehouse-запросы к внутренним и внешним Hive/Hudi таблицам в обоих deployment-режимах.
- Сервисный слой: кэш метаданных синхронизируется с изменениями Hive в реальном времени.
- Доступ: шлюз OneSQL — маршрутизация по кластерам, переписывание запросов и materialized views, авторизация, rate limit и circuit breaker.
В результате фрагментированные сценарии съехали на один движок: озеро, OLAP в реальном времени, онлайн-отчёты и полнотекстовый поиск.
На уровне архитектуры зафиксировали:
- Медленные запросы < 5%, общее ускорение запросов порядка 20–90%.
- Горизонтальное масштабирование эффективнее ~в 10 раз, чем у прежней Elasticsearch-схемы, при поддержке триллионных таблиц.
- Проще эксплуатация: один движок на все типы запросов, меньше зависимостей.
- Полная наблюдаемость: end-to-end трассировка и мониторинг Doris сократили среднее время troubleshooting примерно на 80%.
Миграция и оптимизация
Миграцию разбили на три фазы, чтобы не рвать бизнес-процессы:
- Фаза 1 — пилот: сценарий keyword promotion; полные и инкрементальные пайплайны загрузки; параллельная «двойная» валидация согласованности данных и корректности запросов.
- Фаза 2 — ядро: перенос цепочки «ClickHouse + join с Elasticsearch», импорт всех материалов из Elasticsearch в Doris, отключение кластера Elasticsearch после cutover.
- Фаза 3 — полное покрытие: оставшиеся сценарии только на ClickHouse (без join с ES) — завершение унификации.
Дальше — ключевые технические решения по ходу миграции.
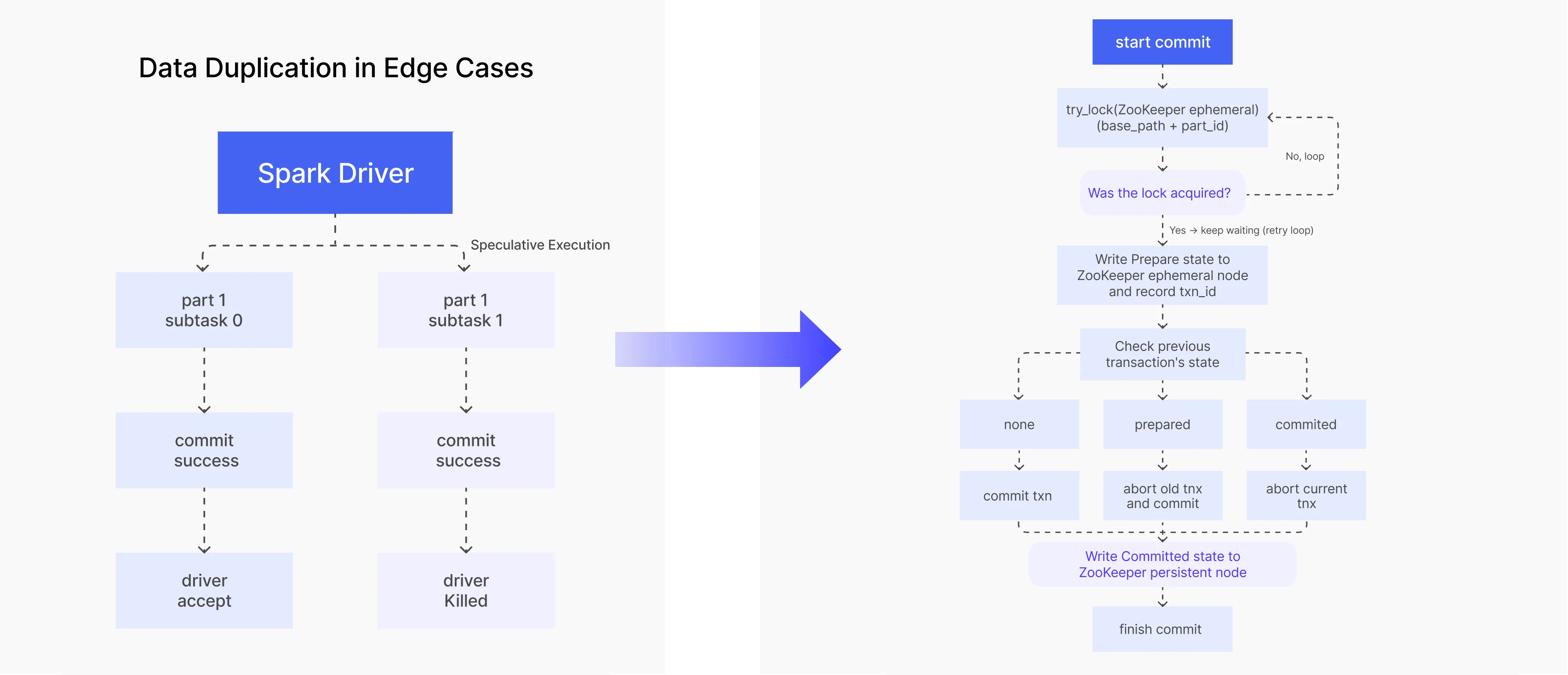
Согласованность данных: распределённые блокировки
Потоковую синхронизацию делали через Apache SeaTunnel, для батчей — семантика перезаписи; импорты шли с two-phase commit для eventual consistency. В связке SeaTunnel + Spark всплыли дубликаты в пограничных случаях:
- Speculative execution в Spark: два варианта задачи могли оба дойти до commit в Doris — данные записывались дважды, хотя Driver засчитал одну попытку.
- Падение задачи после commit: если исполнитель успел закоммитить в Doris, но не успел отрапортовать Driver, тот перезапускал задачу и снова коммитил те же данные.
Решение — распределённый замок ZooKeeper вокруг двухфазного коммита:
- Перед commit взять ephemeral lock в ZK — в потоке commit одновременно только одна транзакция.
- После захвата записать состояние
Prepareи ID транзакции в ephemeral-узел. - Сверить состояние предыдущей транзакции:
- нет предыдущей — коммитим текущую;
- предыдущая в
Prepare— откатить её, затем коммит текущей; - предыдущая уже
Committed— откатить текущую (дубликат).
- Финализировать операцию записью
Commitв persistent-узел ZK.
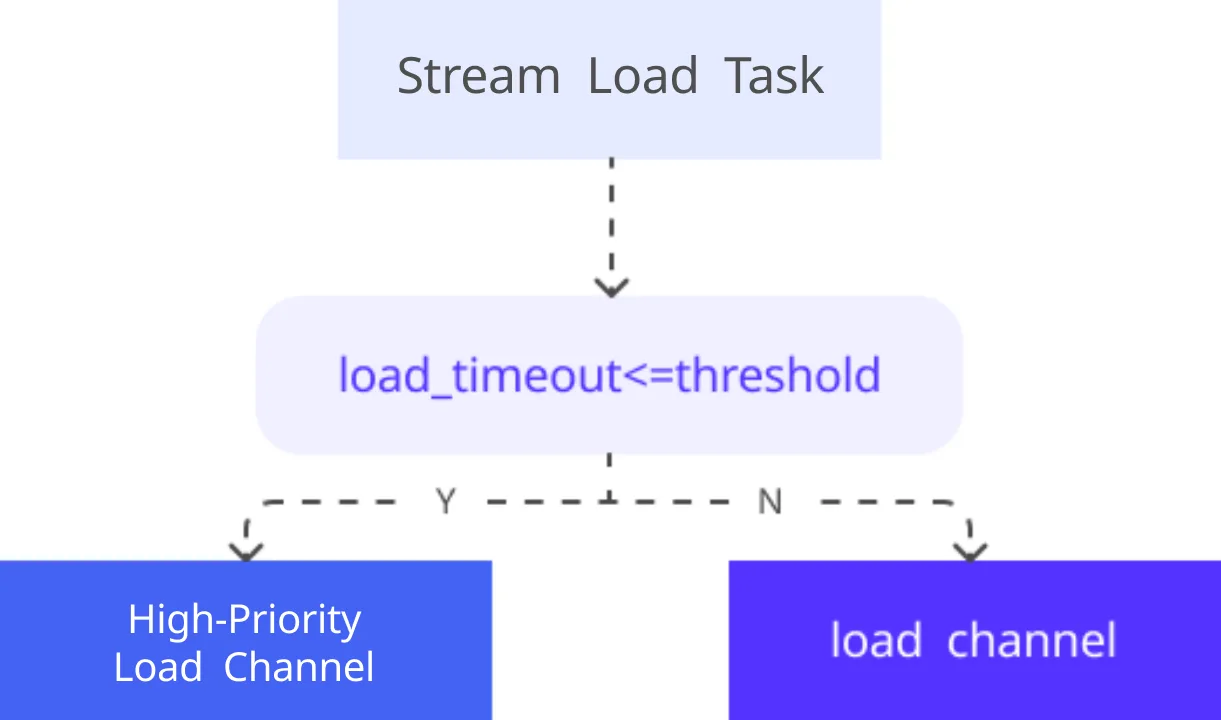
Stream Load под высокую запись
Для высокой конкуренции записи настроили Stream Load в Doris: приоритеты задач и параметры compaction дали прирост пропускной способности и стабильности. Планировщик использует Load Channel с отдельными каналами для высокого и обычного приоритета: если timeout Stream Load < 300 с, задача считается высокоприоритетной.
Пример набора параметров:
load_task_high_priority_threshold_second=300
compaction_task_num_per_fast_disk=16
max_base_compaction_threads=8
max_cumu_compaction_threads=8Проектирование таблиц: материалы и метрики
Для двух классов данных выбрали разные модели.
Таблица рекламных материалов — частые обновления и крупномасштабный поиск:
Фильтрация в бизнес-запросах в основном по account_id, а не по автоинкременту id из MySQL. Для prefix index и sort key в Doris взяли составной ключ (account_id, id) с ведущим account_id и bucket по account_id. Инвертированные индексы — для многомерного поиска, ZSTD — баланс размера и I/O.
-- Таблица материалов: Unique Key + inverted index
CREATE TABLE ad_core_winfo
(account_id BIGINT NOT NULL,
id BIGINT NOT NULL,
word STRING,
INDEX idx_word (`word`) USING INVERTED...)
UNIQUE KEY(account_id, id)
DISTRIBUTED BY HASH(account_id) BUCKETS 1000;Таблица метрик эффективности — агрегации по многим измерениям:
Модель Aggregate, автопартиционирование по дню или часу.
-- Метрики: Aggregate + auto partition
CREATE TABLE ad_dsp_report
(__time DATETIME,
account_id BIGINT, ...
`ad_dsp_cost` BIGINT SUM,
...)
AGG KEY(__time, account_id, ...)
AUTO PARTITION BY RANGE(date_trunc(`__time`, 'hour'))()
DISTRIBUTED BY HASH(account_id) BUCKETS 2;Сдвиг данных по крупным аккаунтам
На стресс-тестах вскрылся перекос: объёмы по account_id от единиц строк до миллионов — сильный дисбаланс CPU на BE. SHOW DATA SKEW показывал tablet'ы по 3–4 ГБ против 100–200 МБ; запросы «тяжёлых» аккаунтов тормозили.
A. Range-партиционирование по Account ID
ID аккаунтов — 5–8 цифр (не более 10). Через FROM_UNIXTIME перевели в тип даты/времени и резали по месяцам: 33 исторических партиции, до 2 592 000 аккаунтов на партицию; новая партиция нужна примерно каждые 2 млн новых аккаунтов. Исторические партиции бакетировали вручную по объёму, новые по умолчанию — 256 бакетов. Это дало эффективное partition pruning при ~300 млн новых строк материалов в сутки.
B. Вторичное хеширование
Чтобы размазать «китов» внутри партиции, ввели поле mod как ID MOD 7 (поле id независимо от account_id), значения 0–6. Ключ распределения сменили с одного account_id на (account_id, mod) — данные одного рекламодателя раскладываются на 7 BE.

После доработок размер tablet'ов стабилизировался около 1 ГБ, нагрузка по CPU выровнялась.
Планирование запросов при 10 000+ партиций
Рост числа партиций дал новый узкий участок: простые point-запросы занимали 250 мс при цели < 100 мс. В Doris 2.1 отсечение партиций делалось линейным проходом по списку — при десятках тысяч партиций это становилось дорогим.
Команда отсортировала партиции и применила двоичный поиск вместо полного скана: сложность с O(n) до O(log n), задержка с 250 мс до ~12 мс (порядка 20×). Изменение вошло в релиз Apache Doris 3.1.
Настройка конкурентности
Парадокс: даже для крупных аккаунтов после фильтрации оставались лишь миллионы строк, а в профиле запроса Total Instance доходил до 800 из‑за дефолтной конкурентности 32 — избыточный параллелизм для маленького результата размножал RPC и задержку.
Снижение параллелизма:
set global parallel_exchange_instance_num=5;
set global parallel_pipeline_task_num=2;Total Instance упал с 800 до 17; задержка point-запросов — с 220 мс до ~147 мс, плюс вырос запас по QPS на кластере.
Результаты и планы
После полной миграции и тюнинга цифры совпали с ключевыми KPI выше: −64…90% по задержкам, >3× запись, ~60% экономии хранения относительно Elasticsearch, триллионные таблицы в комфортном режиме.
В планах на Doris — два направления:
- Полнотекст и токенизация: BM25 (Doris 4.0), токенайзеры вроде IK для разных сценариев.
- Векторный поиск: валидация и оптимизация vector search на внутренних и внешних lake-таблицах на базе возможностей Apache Doris 4.0.
Резюме
Кейс Kwai показывает, что консолидация ClickHouse и Elasticsearch в одном Apache Doris даёт и ускорение отчётности, и экономию хранения, и нормальную сквозную наблюдаемость. Материалы, метрики, lakehouse-SQL и полнотекст укладываются в один контур.
Детали по Apache Doris — в сообществе Apache Doris в Slack. Управляемый сервис — VeloDB Cloud.
Источник
Zhou Simin, «From ClickHouse + Elasticsearch to Apache Doris: How Kwai Unified Trillion-Scale Ad Analytics», VeloDB Blog, 2026-03-20.